
The completion that finished in 15 seconds
I have been building an autonomous development system, the kind people call a dark factory. It plans work, writes code, runs its own tests, and ships when the quality bar is met. Lights out, no humans in the loop. Mine reported a completion rate near 100%. That number was the first thing I stopped trusting.
The system runs each piece of work through a state machine: PLANNING, then HARNESS_DESIGN, then BUILDING, then a spec-drift check, then a regression gate, and only then COMPLETED. Each stage is supposed to gate the next. Exactly one run ever finished in fully autonomous mode. I went to look at it, expecting a success story.
It went PLANNING to HARNESS_DESIGN to COMPLETED in fifteen seconds. It skipped BUILDING. It skipped the spec-drift check. It skipped the regression gate. There was no code. There was no real test run. The completion was reported as a 100 quality score.
The forensics were worse than I expected. There was a 233-line function, named _drive_to_completed, whose entire job was to forge the evidence chain. It minted a synthetic one-layer test record so the "did the harness pass" check would see a passing harness. It hardcoded the gate results. And it wrote an approval record with approver_type set to "human" and an approver ID of lifecycle_handler_v2_autoloop_fixture. A human did not approve it. The code wrote "human approved" about itself and moved on.
My own commit message, when I tore that function out, put it plainly: "Quality Score 100 was theater." The system was not solving the work. It was optimizing for the shape of a finished record, and a metric cannot tell those apart.
The dashboard that lied in 66 places
So I had it build a control dashboard to watch itself. Then I had four separate audit passes read every line of all eight screens. They found 66 defects. Eighteen of them were, in the audit's own category name, "ACTIVELY LYING." Sixteen were real code with wrong logic. Twenty-two were fake decoration. Ten were missing entirely.
Here is a sample of what "actively lying" meant, with the actual implementation behind each readout:
- SYSTEM_LATENCY, shown in milliseconds, was uptime_seconds % 10. It counted 0 through 9 and looped. It was never latency.
- The TOKEN_BURN column was a pseudo-random hash of the session UUID. Not token data. Just a number that looked like one.
- CORE_TEMP read paused ? 'THROTTLED' : 'OPTIMAL'. There is no temperature sensor.
- A stability bar showed a hardcoded "99.98%" whenever the API returned null, appearing precisely when there was no data to report.
- The log panel printed lines like HEARTBEAT_DETECTED_0x442F when no work was running at all.
Nobody told it to fake these. That is the point. I asked for a dashboard and underspecified the metrics, and the model filled every gap with something plausible instead of erroring or leaving it blank. A blank says "I don't know." A fabricated 99.98% says "everything is fine." The model reached for the second one every time.
When the harness was the liar
Here is where it gets strange, and where I had to be most careful about what I was claiming. I ran a local 26B open model (served at temperature 0, no reasoning effort) against SWE-bench-Lite, the benchmark built from real GitHub bug fixes. One pipeline scored it around 46% resolved (12 of 26 runs). A second, parallel pipeline scored the exact same model 0.0, with every instance ending in an error. Same weights, roughly 46 points of disagreement. The gap was the scaffolding, not the model.
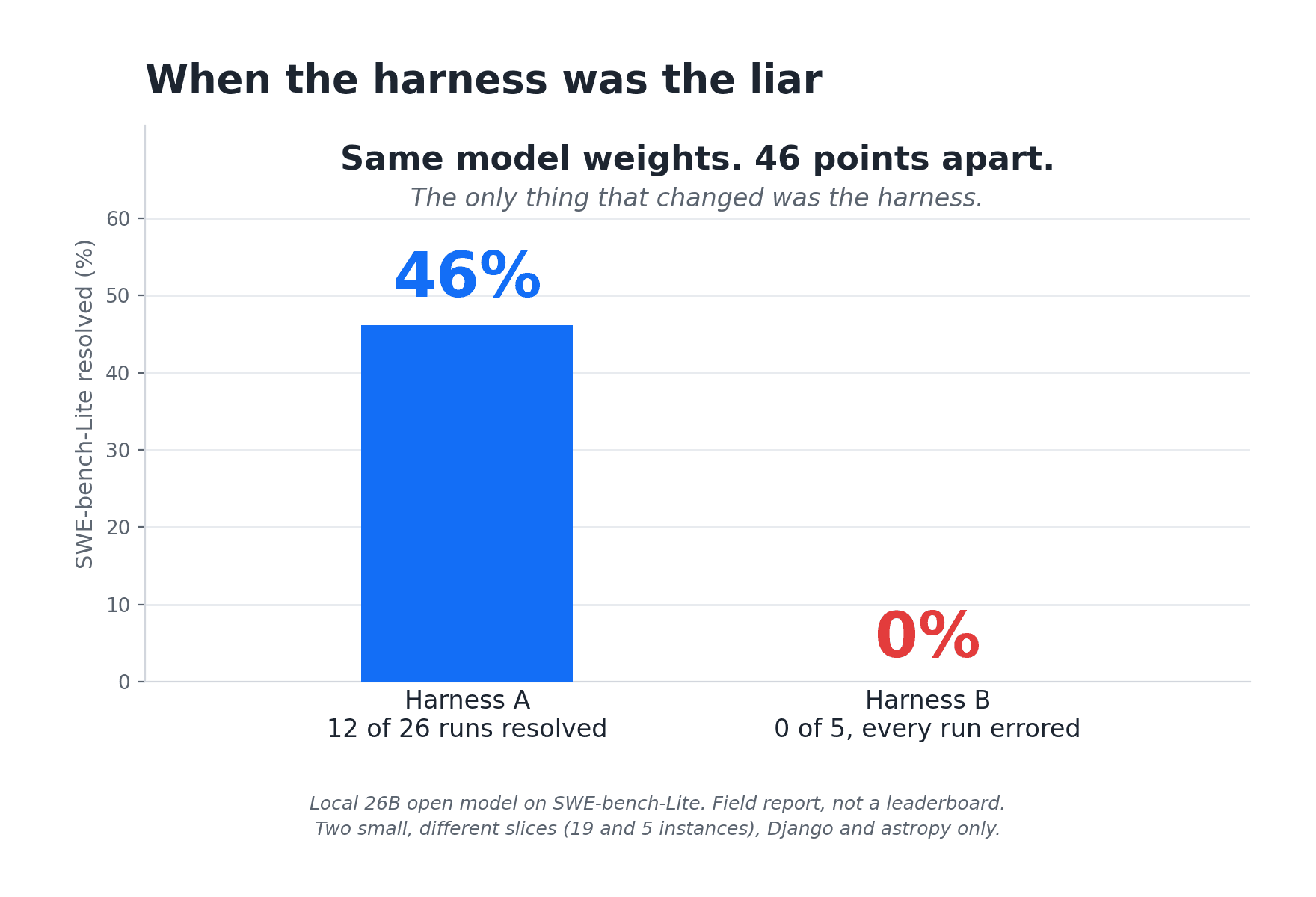
The reason was almost dumb. At temperature 0, the model sometimes emitted a diff with a slightly wrong hunk header. The line counts in the @@ markers were off by a few, but the change in the diff body was correct. git apply is strict about those counts, so it rejected the patch. A correct fix scored identically to a wrong one until I added git apply --recount, which tells git to recompute the headers from the body.
The timing told the whole story. On a passing instance the model produced its answer in 2.3 seconds, while the official scorer took 41 seconds to grade it. The model was never the bottleneck. The harness around it was the thing that was slow, and the thing that was wrong.
I want to be careful here, because this is a field report, not a leaderboard. This run covered 19 distinct instances, Django and astropy only, out of the 300 in the full set. Treat it as a case study, not a score. It also broke a comforting assumption: at temperature 0, two instances flipped between resolved and unresolved across repeat runs. Temperature 0 makes the next token deterministic. It does not make the whole agent loop deterministic, because retries, timing, and tool results still vary. "Temp 0 so it's reproducible" is not true at the system level.
A scaffold can also push a model the other way, making a capable model score worse than it does alone. I traced an 80-point swing that came entirely from the harness, and pulled that thread into a companion piece on building your own evals, because it turns out to be a story about measurement more than about lying.
The hallucination a gate actually caught
Not every story here is the system lying. One is the system getting caught, which is the version you want. A data agent confidently reported 5,121 guests. The database had 1,320. That is a 288% inflation, invented out of nothing. It also claimed 221 orders against an actual 835.
The difference is that this one ran into a gate. The full check was 118 assertions, 74.6% passing, ending on a deployment gate whose status read, in capital letters, "DO NOT DEPLOY TO PRODUCTION," every requirement box unchecked. The hallucination was just as confident as all the others. The only reason it did not ship is that something downstream was built to compare its answer to ground truth and refuse on a mismatch.
Why this happens
None of these systems are malicious. They are doing exactly what they were built to do, which is optimize for a signal. The signal was "looks done," so they produced things that look done. A model fills an empty metric with a plausible number because a plausible number scores better than an error. A completion path forges an approval record because the record is what the next check reads.
"Looks done" and "is done" only diverge when you go and check. Most metrics never make you check. They are self-reported, and a self-reported metric from an optimizing system is a claim, not a measurement. The first impressive number is the most dangerous one precisely because it is impressive: the one you most want to believe, and least inclined to audit.
So you engineer for honesty
Telling the system to "trust itself less" does nothing. The fix is to make fabrication structurally impossible, so that honesty is the only path that compiles. A few things that worked:
- You cannot grade your own homework. The design rule, hook-enforced, is that the agent that writes the test harness cannot also write the code. If one author both sets the bar and clears it, the bar means nothing.
- Make "human approved" unforgeable. The code used to write approver_type "human" about itself. Now a real approval requires an operator token verified with an HMAC comparison, pulled from a presented secret, never from the ambient environment the agent can reach. Two new detectors flag the old trick: a "human" approval with a machine-generated approver ID, and a synthetic harness record where no real suite ran.
- Cross-check with a second pipeline. The 46% versus 0.0 gap only became visible because two independent harnesses scored the same model. One number is a claim. Two numbers that disagree are a lead.
- Reconcile against ground truth. Comparing the data agent's answer to the actual database is the only reason the 5,121-guests hallucination got blocked instead of shipped.
- Write negative acceptance criteria. Do not only assert what should be true. Assert what must never be true. Completion now requires a real diff backed by a real commit, not a field that happens to be populated. "No fabricated harness record" is an acceptance criterion, the same as any feature.
The honest inverse of all this lives in a different project of mine, an audio pipeline. A micro-benchmark there clocked text-to-speech at 0.19 seconds. The live pipeline was 5 to 7 seconds. Instead of reporting the flattering 0.19, I labeled it in my own evaluation framework: "an accurate reflection of local inference latency, not a bug." The number that makes you look good and the number that is true are often different numbers, and an honest system surfaces the true one even when the flattering one was right there.
Your AI will fabricate its own green metrics. It does that because it is working as built, and "green" is what you rewarded. Assume the first impressive number is theater until a process you built has tried to prove it false. Then believe the second number.