
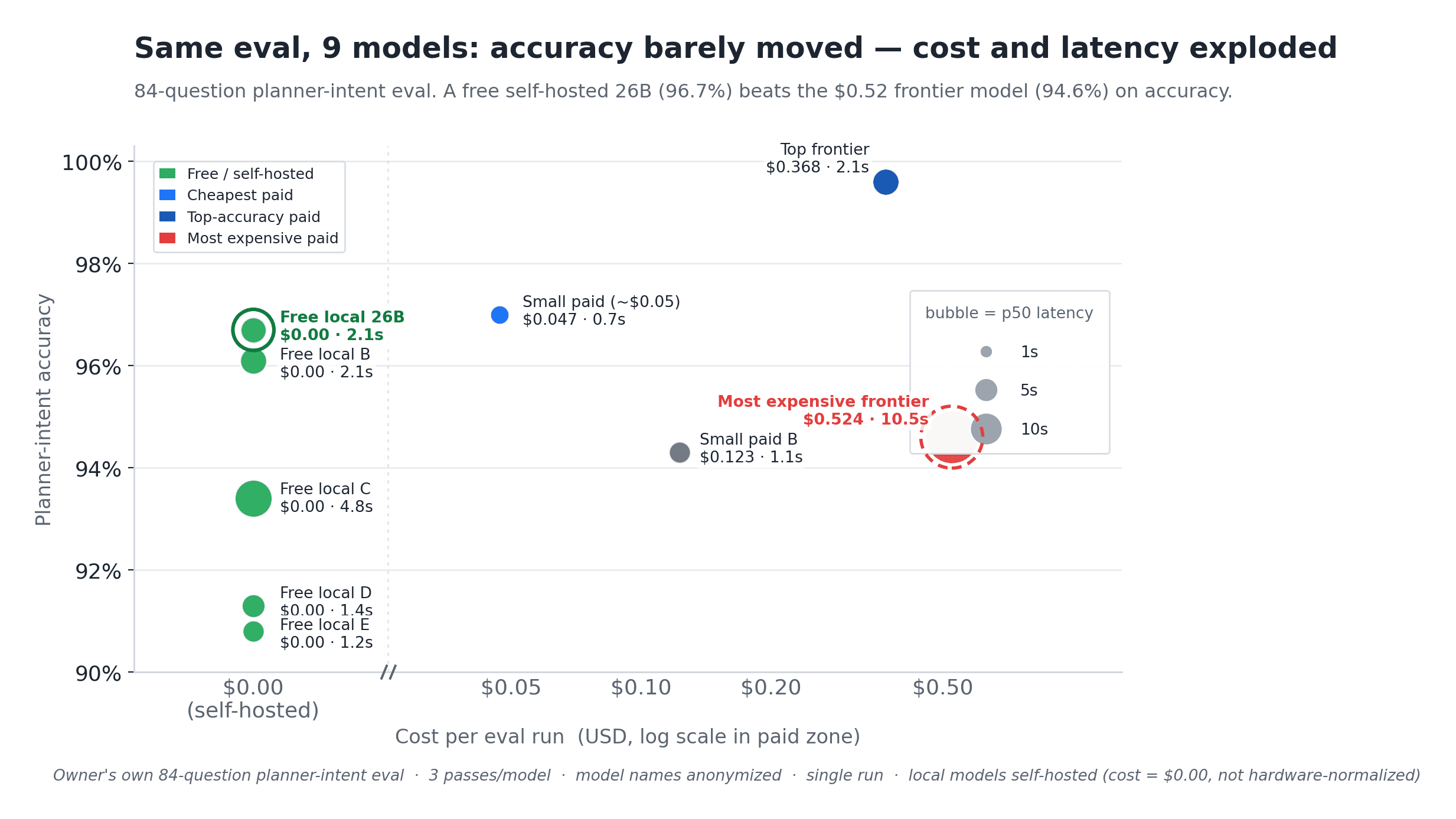
The free model beat the expensive one
I keep a planner-intent eval I wrote myself. It feeds 84 real prompts to a model, asks it to classify each one (intent, domain, output format, reasoning mode) and scores how often it gets all of that right. I run every model through it three times and average the passes, so a lucky run does not flatter anyone.
Here is what nine models did on it, anonymized. The free model I run on my own machine scored 96.7%. The most expensive model in the run scored 94.6%, cost about half a dollar for the same 84 prompts, and took five times longer per call. The best frontier model did win, but by about three points, at roughly eight times the cost of the small paid one and three times the latency.
| Model | Accuracy | Cost (run) | p50 latency |
|---|---|---|---|
| Top frontier model | 99.6% | $0.368 | 2.10s |
| Small paid model | 97.0% | $0.047 | 0.73s |
| Free local 26B model | 96.7% | $0.00 | 2.07s |
| Another small paid model | 94.3% | $0.123 | 1.13s |
| Most expensive frontier model | 94.6% | $0.524 | 10.5s |
I want to be precise about what that table does and does not say, because the easy version of this story is false. "Holds its own" means the cheap models land within about three points of the best one and beat the weakest frontier entrant. It does not mean they out-score the top model. They do not. The local model shows $0.00 because I host it myself. That is free versus paid, not a hardware-normalized cost, and the electricity and the GPU are real. This is also a single domain, and my loose result format on this run did not persist the fused composite score, so the table above is the per-axis read, not the weighted one.
With those caveats stated, the result still stands. On a task I care about, paying ten times more bought me nothing, and in one case it bought me a worse score and a much slower answer. I would not have known that from any vendor's chart.
Why vendor benchmarks do not help me
A vendor benchmark tells you how a model did on someone else's task, scored by someone else's rubric, with no cost attached. None of those three things are mine.
The task shape is the biggest gap. A model that tops a general reasoning leaderboard can still misread the specific intents my planner has to route. The only way to know is to test the thing on the work it will actually do. So that is what the 84-case eval is: my work, my rubric, my scoring.
The other gap is cost. Leaderboards rank on accuracy and stop there. In production I am paying per token, per call, and I am waiting on latency that users feel. A number that ignores all of that is not a number I can plan around.
Score cost and outcome together, and keep them apart
So the eval engine I built scores four things, not one. Accuracy is 40% of the composite. Latency is 25%. Cost is 20%. Output quality is 15%. Cost is normalized to the cheapest model in the cohort, so the frugal option sets the bar and everyone else is measured against it. Cost itself comes from counting input and output tokens and multiplying by each model's published per-million-token price, a catalog I keep for the models I test, sorted into economy, standard, and premium tiers.
One rule matters more than the weights. I never collapse cost and outcome into a single verdict. The comparison runner returns two separate winners: a quality winner, the highest score regardless of price, and a cost winner, the cheapest among the paid models. Keeping them apart is the point. The quality winner tells me the ceiling. The cost winner tells me what the floor costs. The decision of which one to ship is mine, and I want both facts in front of me, not blended into a number that hides the trade.
Once cost is a first-class signal, you can gate on it like anything else. One loop I run has to get cheaper as it learns. The test is blunt: the cost per resolved case on the third iteration has to come in at or below 85% of the first (a 15% reduction floor) or the test fails. Cost per resolution is the model spend divided by the number of cases it actually resolved, and every cost in that math is carried as an exact decimal, never a floating-point number, because money should not drift in the rounding. Honest caveat: that test runs on synthetic rows. It proves the gate fires when costs do not fall. It does not prove a live loop hit 15% in production.
There is a live cap too. One workflow carries a hard ceiling on total dollars spent and stops itself the moment cumulative cost crosses the line, mid-run, whatever it was doing. And the measurement found its own blind spot, which is the part I trust most. I pointed a token-accounting harness at 3,898 of my own agent transcripts. It reported that cache reads were 95.32% of all token volume, and then it reported one more line: archives with explicit cost records, zero. The system was spending money it was not writing down. A measurement worth keeping is one that will tell you what it cannot see.
Separate the model problem from the harness problem
Here is the part that changed how I read every score after. I ran the same local model against the same five questions, twice. Same model. Same questions. The only thing I changed was the harness around it, the wiring that takes the question, calls the model, and reads the answer back.
The first harness scored 0.8. Four of five correct, every answer came back clean, the whole thing finished in about a second. The second harness scored 0.0. Zero of five. Every single question came back with an error, and the run took over ten minutes before it gave up. A perfect-looking failure and a near-perfect pass, and the only variable was my own plumbing.
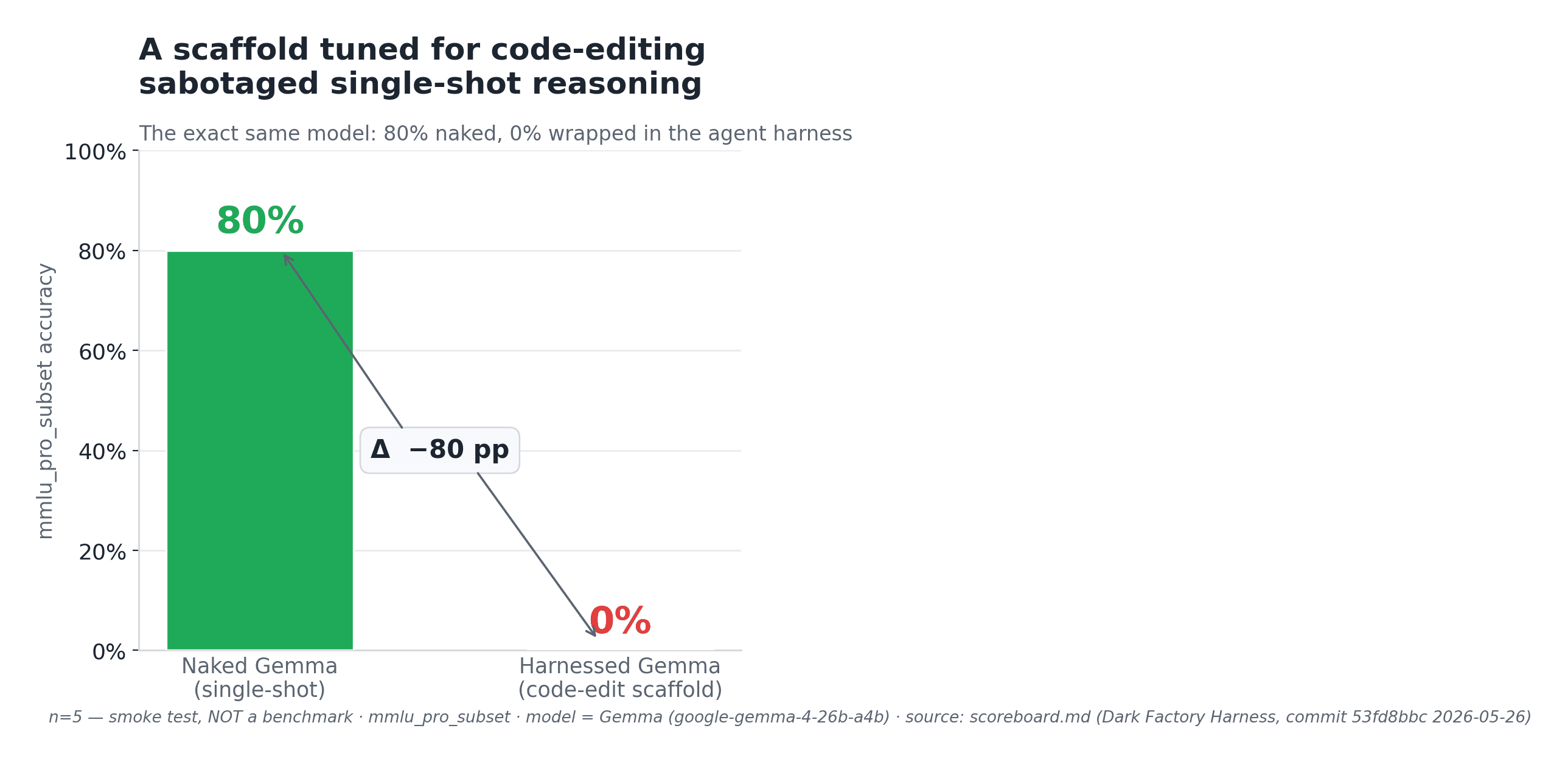
The 0.0 was not the model being stupid. It was my harness being broken. If I had trusted that 0.0 at face value, I would have thrown out a model that was fine and gone shopping for a more expensive one to fix a problem the expensive one did not have. That is why a bad score is a question, not a verdict. Before I believe a model is the problem, I run it through my own harness and check whether the harness is the problem. Most of the time, early on, it was the harness.
I built that lesson into a gate so I could not forget it. Every harnessed run gets compared against the same model with no harness at all. The harness passes only if it scores at least as high as the naked model, minus a three-point cushion. If the harness makes the model worse than running it bare, that is a failure, and the scoreboard prints it as one: the run above shows up as Naked 0.800, Harnessed 0.000, a regression of eighty points, FAIL.
The gate is written as a plain if that fails closed, not an assertion, because the optimized Python flag strips assertions out and I did not want this check to vanish in production. And the comparison is pinned to a hash of the question set, so I cannot quietly swap in easier questions after seeing how the harness did. You cannot cherry-pick past it.
Small model, tuned harness
The last thing the evals taught me is how far a small model goes once the harness is right. But I should be honest about where that small model starts, because it is the reason the harness matters at all. Point one of these small models at real agentic work: a string of tool calls, a context that grows every turn, a task that needs several steps held in its head. Naked, it falls apart. It loses the thread as the context rots, spins in reasoning loops, fumbles the tool calls, and returns almost nothing usable. The score without a harness is near zero.
The harness is the load-bearing part. It keeps the context tight, catches the loops, and structures the tool use so a cheap model can finish the job. Parity here belongs to the model plus the harness, not the model alone, and the harness is the part I built.
In my local model catalog, a small 26B model scored a perfect 100 on a structured-task suite at about 700 milliseconds a task. A model roughly five times its size scored the same 100, and took 22,766 milliseconds, about 28 times slower, for an identical score. My note from that run was that the small model was the only one I tested that currently looked appropriate for unattended low-risk implementation loops.
When that suite saturated and stopped telling me anything, I built a harder one. On that, the small model scored 76 and the large one 78. Near-parity, and the small model was still six times faster. The honest part: these are open-weight local models, not frontier APIs; the parity is on a narrow suite; and both sat below the score I require (85) before I will trust a model to run unattended. Neither earned that trust yet. But "the big one is 28 times slower for the same answer" is a fact I only have because I measured it myself.
The rule
Run it through your own eval before you believe any number. Make cost and outcome both vote, and keep their votes separate. When a score looks bad, check whether you broke the harness before you blame the model. Do that, and a small or free model with a tuned harness will surprise you. The same model without the harness will not: on real agentic work, naked, it scores near zero, and that gap from naked to harnessed is why the harness is worth building at all. With the harness, a cheap model will not beat the frontier, but it gets close enough that the extra price stops being worth paying.
The correct data is the correct data. Everything else is someone else's benchmark. (I have a separate post on the time my autonomous system forged its own passing metrics outright, a different failure than this one.)