
The most honest artifact in the project
A model I tuned this week generated this, verbatim, the first time I asked it to take an action on a repository:
Act as the diffuser
Act as the diff weigh lenght reviews... <|turn|><|turn|><|turn|>That is not a typo. That is a 4-billion-parameter model that had just finished training, with a training loss that looked great, producing literal garbage. I kept the output. It is the most honest artifact in the project, so I will start there and work backward.
What I was trying to do
I run an autonomous development orchestrator. It routes a feature through phases, reads a verification harness, and makes calls: advance, reroute, kill a builder, or stop and ask me. It works, but a large frontier model is doing the deciding, and that is slow and expensive to run on every small decision.
So this week I tried to distill those decisions into a small local model, a LoRA fine-tuned on Apple Silicon, trained on my own real sessions, lifecycle archives, and orchestrator logs. About 104,000 records to start. The pipeline landed June 5 and I extended it through the 8th. The dataset is on its sixth revision.
I want to be precise about what this is. It is a working prototype and a methodology I now trust. It is not a model that replaces me. The eval lifts are smoke-scale. One class of data is still partly duplicated, and I will show you that number rather than hide it. The value is what the data taught me, not the model I shipped.
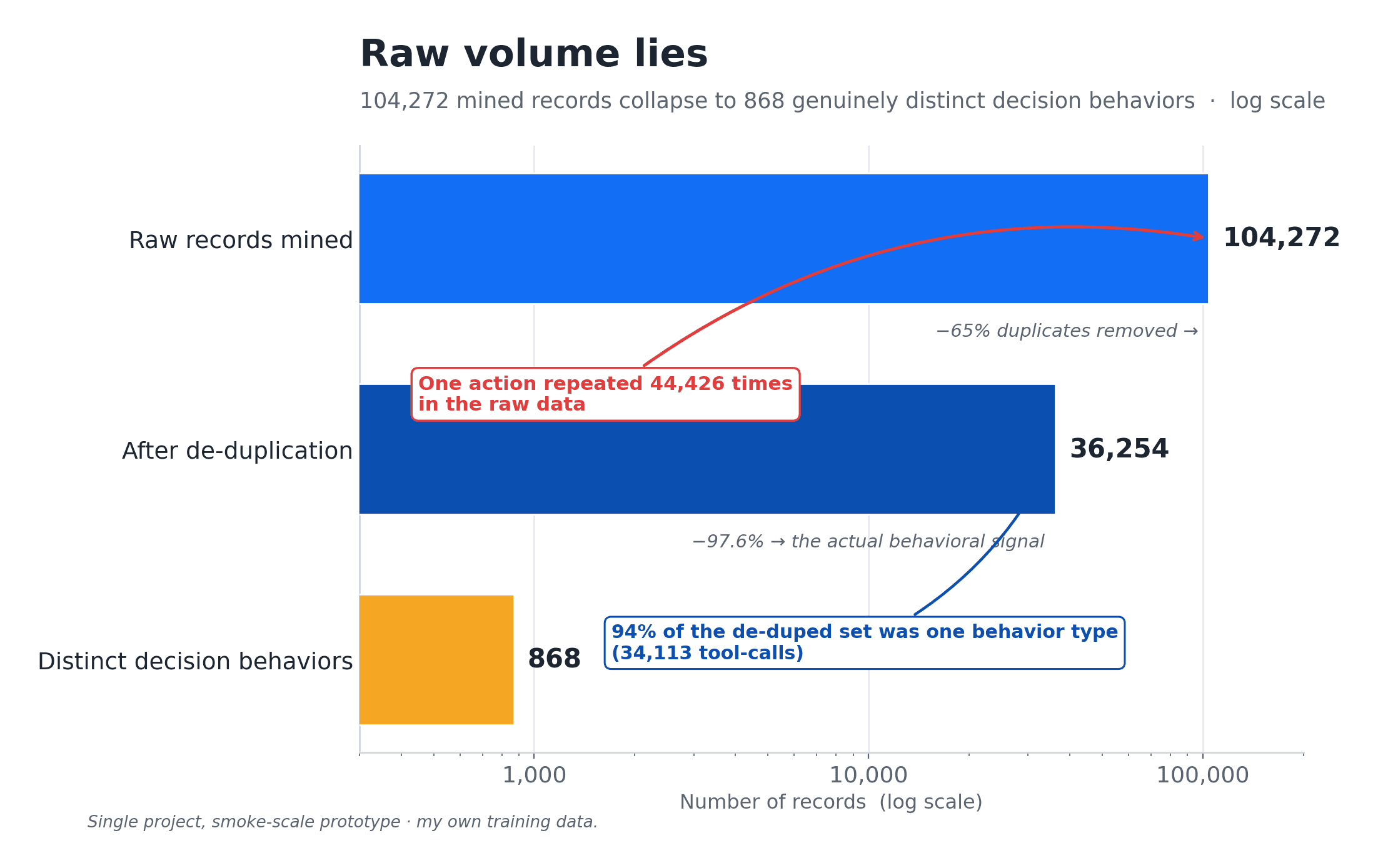
Raw volume lies
The first thing the data taught me is that 104,000 records is a vanity number.
After deduplication I had 36,254. Of those, 94 percent were a single behavior: tool-calling, 34,113 of them. One degenerate action, an auto-escalation to the orchestrator, appeared 44,426 times in the raw data. Near-duplicate dedup does not catch it. Each instance has slightly different surrounding context, so by string similarity they all look distinct.
They are not distinct in any way that matters for training. My decision-policy bucket, the actual judgment calls, collapsed to 868 distinct behaviors. I had been calling them 45,000 decisions. They were about 868.
The fix is to stop counting rows and start counting behaviors. I cap each (type, action) bucket so no single pathway can dominate, and I keep a diverse sample of every behavior instead of ten thousand copies of one.
The collapse attractor
The second lesson is why that garbage output happened.
A model memorizes whatever repeats most. My earlier dataset had two repetition problems at once. The inputs were templated: the same system prompt, the same scaffolding wrapped around every sample. And the targets were terse and near-identical. I had 271 copies of a single phrase, "gate is GREEN; advances," sitting in the training set.
When you train on that, the loss craters in a few iterations because the model has found the shortcut. It stops answering and starts reproducing the most-repeated span it saw. On one base that came out as the system prompt echoed back. On the vision base it came out as the token salad above. The fifth revision of my dataset collapsed for exactly this reason, and I wrote the cause straight into the next script: the v5 collapse was input-template memorization.
Enrichment is regenerating the targets, and measuring it
So the targets had to change. A terse target teaches the model nothing except the terse target.
I used a swarm of a large frontier model as teacher to regenerate each terse decision into grounded, varied reasoning. The rule that makes this safe is that every regenerated target is grounded in that sample's own real evidence: its actual diff, its actual outcome. The teacher reasons from the source artifact toward the decision that was actually made. It does not invent.
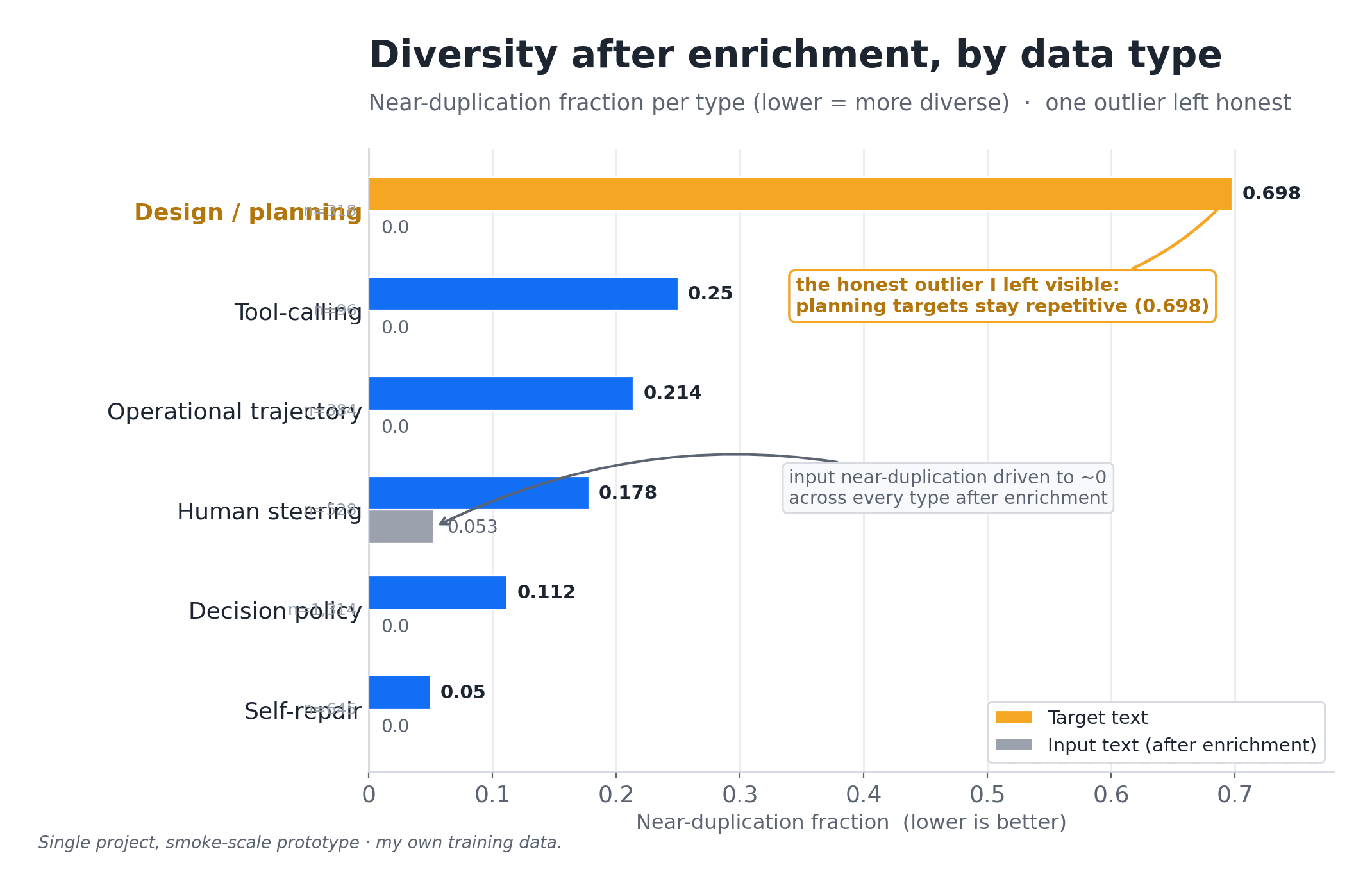
The part I had been skipping in earlier attempts was measuring the result. Diversity is not a vibe. I score two things per type: the mean cosine similarity within the type, and the near-duplicate fraction. After enrichment, input near-duplication dropped to 0.0 across nearly every type, with mean cosine around 0.06. One swarm run took 2,764 source rows and produced 5,527 varied variants, zero misses, across five workers. Now I have a number that tells me whether the diversity problem is fixed, instead of a hope that it is.
The self-teardown
This is the part I am most willing to stand behind, because it is where I let someone gut my work.
I ran an adversarial review against my own first dataset. The verdict came back: "FIX-FIRST. This dataset is useful as a prototype, but not fit to train an orchestrator that replaces a human operator." Then it listed the reasons, and they were all correct.
The label was circular. "Worked" mostly meant the change survived on the main branch. That mislabels good work that lived off-main as failure, and rubber-stamps anything that happened to land. The label was measuring git reachability and calling it judgment.
There was an anti-escalation bias baked into the prompts. I had been teaching the model to never punt to a human when it could make a call. On a system meant to operate autonomously, that teaches false confidence, exactly the failure you cannot afford.
And the hard negatives were fake. My rejected examples had a median length of 185 characters; the chosen ones, 446. A preference model trained on that does not learn good judgment. It learns that the longer answer wins.
So I wrote a third build that fixed each finding by name. Every preference pair is now length-normalized to within 12 percent, so the model cannot win on length. The split is by connected component over feature, commit, source reference, and session, so no work leaks across train and test. No single feature can exceed 8 percent of the set. And I dropped an entire class, route-to-human, after finding that 0 of its 104 "positive" examples were a case where a human was actually required. They were self-correctable mistakes wearing an escalation label. A class that is 0 percent real is a bias generator.
A review that only confirms your work is worthless. This one was worth the sting.
Two quiet lessons about hygiene
Two more things, less dramatic, that I had not appreciated before.
The first is de-identification, done twice. This data is mine: real sessions, real paths, real names. I scrub it once on the way into enrichment, so the teacher never sees a secret, and again as a final gate on the assembled set. Three layers: a denylist that drops a whole sample on a banned term, deterministic regex for keys and paths and machine identity, and a slow privacy-filter model for what regex misses. On one pass that was 55,215 deterministic redactions across 36,254 records, with a residual leak count of zero on the final gate.
The second is subtle enough that I almost missed it. Because I ground enrichment in the actual outcome (did this change survive), the teacher starts reasoning from hindsight. It writes things like "this survived on main, therefore approve." That is a tell the model will not have at inference time, when it has to judge a decision before knowing how it turns out. So at assembly I strip the outcome-anchored sentences out of the target text while keeping the outcome in the label. The model still gets graded on the right answer. It just cannot cheat its way there by leaning on a fact it will never have in production.
NLL is a liar
Which brings me back to the garbage output, and the one rule that saved this project from a fake success.
Teacher-forced training loss can fall to 0.0001 while the model, left to generate on its own, produces nothing but loops and tokens. Loss is computed with the right answer already in hand at every step. Generation is not. They can disagree completely.
So I never trust the loss curve. I gate on free-running generation: give the model the prompt without the answer, let it generate, parse the canonical (verb, target) out of what it produces, and require coherence of at least 0.9 on a held-out slice of at least 60 samples. That is what caught the VLM collapse. The loss looked fine, the generations were token salad.
It also produced the most useful meta-lesson of the week. A 6-billion-parameter text model on a mature trainer beat a 26-billion-parameter vision model on an immature one. The dataset was always fine. The blocker was the trainer and the modality, and only generation-based eval made that legible. On the right setup, the small text base went from a full-accuracy of 0.10 to 0.15, with verb accuracy from 0.25 to 0.367 and coherence at 0.90, a genuine lift, and still firmly smoke-scale.
Where it actually stands
So here is the honest state. The pipeline works. The methodology is sound, and I will reuse it on the next source. The eval lifts are small and noisy at n=60, with full-accuracy somewhere in the 0.07 to 0.15 range depending on the slice. This is a prototype.
And one wart I am leaving in plain view: my v6 diversity report shows that for one class, design-planning, the target near-duplication is still 0.698. Almost every other class is near zero. That one is not. I measured it and shipped it visible rather than rounding it away.
That is the point. The model is a prototype. The measurements are the product. If I had trusted the loss curve and the row count, I would have a confident model that generates garbage and a dataset that lies. Instead I have a small model that honestly beats its base on a few axes, a stack of numbers that tell me where it is still weak, and a 0.698 I have not fixed yet.