
The gap that reorganized how I think about local inference
Local AI inference posts usually show one benchmark number and stop. This one keeps going past the number, into what happened in production.
I benchmarked 18 text-to-speech models on one Mac. My fastest (0.19s) became a nine-second wait once it ran inside a live voice pipeline. A reasoning model would not stop thinking. And concurrency on a single Mac turned out to mean a queue. I measured it: 2.84x slower at three simultaneous sessions.
Real numbers, real footguns, a reproducible how-to, and an explicit list of where the figures are soft, including the ones I re-measured for this post and found worse than the docs claimed.
One caveat up front, stated loudly because it changes how you should read everything below: nearly all of these numbers come from a single machine (an Apple M3 Ultra with 512GB of RAM, the high end of the lineup), and most are single-run. If you are on an M1 or M2 Air, you will see worse. I flag the soft figures as I go and list them again at the bottom.
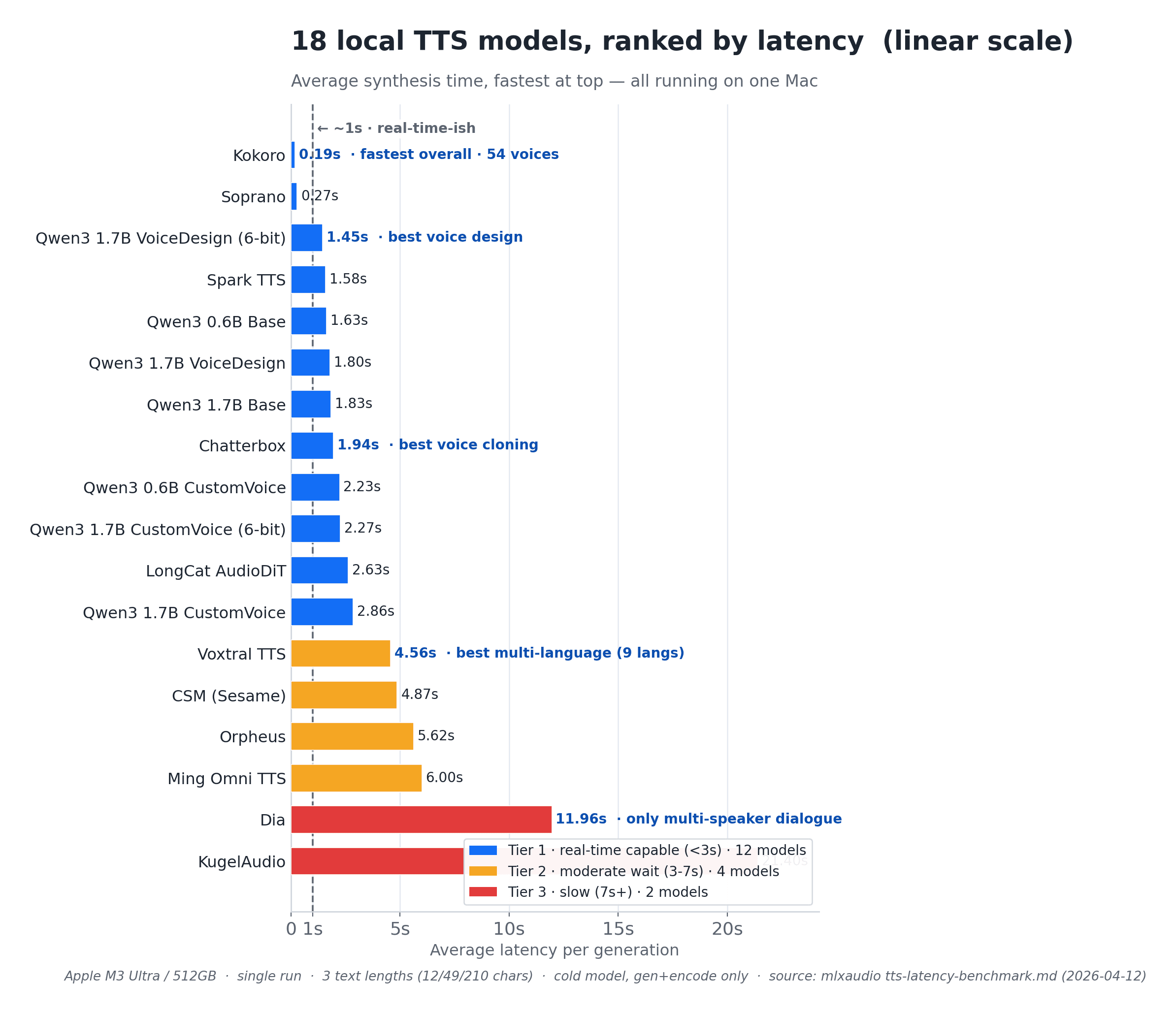
The headline: 18 TTS models, one Mac, a 100x spread
I loaded 18 TTS models and timed each one against three text lengths: short (12 characters), medium (49), and long (210), writing WAV out, with max_tokens=800, and the model already loaded. That excludes load time by design. Hold that thought, because it matters a lot in the next section.
The spread is the story. Fastest to slowest is roughly 100x: Kokoro averages 0.19s; KugelAudio averages 21.4s and hits 44.70s on the long text. Here is the full table, sorted by average latency.
| Rank | Model | Short | Medium | Long | Avg | Tier |
|---|---|---|---|---|---|---|
| 1 | Kokoro | 0.08s | 0.10s | 0.40s | 0.19s | 1 |
| 2 | Soprano | 0.09s | 0.14s | 0.57s | 0.27s | 1 |
| 3 | Qwen3 TTS 1.7B VoiceDesign (6-bit) | 0.26s | 0.80s | 3.28s | 1.45s | 1 |
| 4 | Spark TTS | 1.29s | 0.80s | 2.63s | 1.58s | 1 |
| 5 | Qwen3 TTS 0.6B Base | 0.32s | 1.04s | 3.52s | 1.63s | 1 |
| 6 | Qwen3 TTS 1.7B VoiceDesign | 0.32s | 0.84s | 4.25s | 1.80s | 1 |
| 7 | Qwen3 TTS 1.7B Base | 0.38s | 0.98s | 4.12s | 1.83s | 1 |
| 8 | Chatterbox | 0.68s | 1.32s | 3.83s | 1.94s | 1 |
| 9 | Qwen3 TTS 0.6B CustomVoice | 1.08s | 1.17s | 4.45s | 2.23s | 1 |
| 10 | Qwen3 TTS 1.7B CustomVoice (6-bit) | 0.30s | 1.10s | 5.41s | 2.27s | 1 |
| 11 | LongCat AudioDiT | 2.38s | 2.38s | 3.11s | 2.63s | 1 |
| 12 | Qwen3 TTS 1.7B CustomVoice | 0.40s | 1.26s | 6.91s | 2.86s | 1 |
| 13 | Voxtral TTS | 1.78s | 2.44s | 9.46s | 4.56s | 2 |
| 14 | CSM (Sesame) | 1.10s | 2.87s | 10.62s | 4.87s | 2 |
| 15 | Orpheus | 2.57s | 3.93s | 10.34s | 5.62s | 2 |
| 16 | Ming Omni TTS | 2.45s | 3.23s | 12.33s | 6.00s | 2 |
| 17 | Dia | 15.53s | 4.89s | 15.47s | 11.96s | 3 |
| 18 | KugelAudio | 4.56s | 14.95s | 44.70s | 21.40s | 3 |
Three tiers fall out cleanly.
- Tier 1, real-time capable (under 3s avg): 12 models. This is where you live for voice.
- Tier 2, good quality, moderate wait (3 to 7s avg): 4 models.
- Tier 3, slow (7s and up avg): 2 models.
The second story in this table is the capability-versus-speed tradeoff. Fast does not mean best for your use case.
- Best voice cloning: Chatterbox at 1.94s, fast, and clones from a reference clip.
- Best dialogue: Dia at 11.96s, the only model here with [S1] and [S2] multi-speaker tags. If you need two voices in one stream, you pay 12 seconds for the privilege.
- Best multi-language: Voxtral at 4.56s, 9 languages, 20 voices.
- Most controllable: Qwen3 CustomVoice at 2.23s, named speakers plus emotion instructions.
Kokoro wins on raw speed because it is a lightweight, phoneme-based model with 54 voices. But if you need cloning or dialogue, the fastest model on the board cannot do your job at all.
Soft-number flag: this whole table is single-machine (M3 Ultra / 512GB) and a single benchmark run. Treat the ranking as robust and the absolute milliseconds as one machine's reading on one day (2026-04-12).
The gap: 0.19s warm, about 9s in production
That 0.19s Kokoro number was measured with a warm model and excluded load time by design. It is a clean microbenchmark of generation plus encoding. Fine, as long as you remember that is all it is.
The project's own docs already admitted a gap: local TTS adds about 5 to 7s to time-to-first-audio, labeled an accurate reflection of local inference latency, not a bug. Rather than trust the prose, I re-ran the eval harness myself over the nine stored runs. End-to-end time-to-first-audio came back at a p50 of 8.8s, tail to about 13.8s (mean 8.0s, min 2.7s, max 13.8s). The casual 5 to 7s was optimistic. Re-measuring moved the number the wrong way, which is the reason to re-measure in the first place.
I also timed the loaded model live: warm Qwen3-TTS-1.7B synthesized a nine-word sentence in about 1.5s wall (real-time factor about 0.5, faster than real time). I did not re-verify Kokoro's 0.19s (it was not loaded, and loading it would have disturbed the running server), so treat 0.19s as the original microbenchmark, not a figure I reproduced today.
Why does the gap matter? Because there is a hard bar for voice. The evaluation framework these numbers were measured against sets one.
- Pass: time-to-first-audio p50 under 1.5s.
- Best-in-class: p50 under 800ms.
So a model that benchmarks at 190 milliseconds warm lands at an 8.8s p50 in production, well past the 1.5-second pass bar, by roughly 6x. The first measured run of the spec scored roughly 51 to 59 composite (the Pilot-only / Not-ready boundary), and the single biggest drag was local-TTS latency.
The cold case is worse. The very first request after a server restart hangs for 30 to 60 seconds, because a cold MLX model downloads weights and JIT-compiles its Metal kernels on first call.
The lesson: a warm microbenchmark and a production time-to-first-audio are different measurements, and the distance between them is where local inference actually lives. Anyone quoting you a sub-second local number who has not told you whether the model was warm is quoting a best case you may never see.
Hardened or soft: production time-to-first-audio is now a logged distribution: p50 8.8s over nine runs, re-measured for this post on an M3 Ultra / 512GB. The 0.19s Kokoro figure was not reproduced today (model not loaded); warm Qwen3-TTS-1.7B measured about 1.5s live. Still soft: the 30 to 60s cold start. I could not restart the shared server to time it, so it rests on config and ops-doc corroboration.
War story: the reasoning model that would not stop thinking (17 to 25s, then 1.1s)
The LLM in the loop had its own pathology, and it is a good one.
The default voice model was a reasoning-finetuned LLM. Left alone, it burned 6,000 to 8,000 characters of hidden chain-of-thought per turn, silently, before saying a word out loud. The result: 17 to 25 seconds of latency and frequent empty dropout replies where it thought itself into saying nothing.
The frustrating part is what failed to fix it. Every obvious knob did nothing.
- enable_thinking: no effect.
- /no_think: no effect.
- reasoning-budget caps: no effect.
They all failed for the same reason: the reasoning was baked into the weights, not gated by a flag. You cannot turn off a behavior the model learned as its native way of operating.
The one lever that worked was server-side: reasoning_effort="none", sent on every request. That got it to 0 reasoning and about 1.1s time-to-first-token, with no dropouts. Without that single flag, my own note says plainly, the model is not usable for live voice.
This is the LLM's contribution to the production pipeline latency from the previous section. Stack a slow-thinking model on top of local TTS and the seconds compound fast.
The transferable lesson: when a model misbehaves because of how it was trained, configuration flags will not save you. You need a lever at the serving layer, or a different model.
The MLX gotcha: it segfaults if two users talk at once
This one cost real debugging time, and it is the least-documented failure mode in local MLX serving.
MLX and Metal are not thread-safe across concurrent .generate() calls on a single model object. The server hands the same shared model instance to every session. So when two browser tabs talk at once, two threads call into the same model in parallel and the worker dies with a native segfault: no Python traceback, nothing to catch. launchd respawns the process, which drops every live session (WebSocket close 1006). One person's second tab kills everyone's call.
The fix is a process-global MLX lock that serializes all in-process speech-to-text and text-to-speech inference across every session on the box. From my own comment in the code: MLX and Metal are not safe under concurrent .generate() calls on one model from different worker threads; two concurrent sessions could call into the same model in parallel and crash the worker with a native segfault: no Python traceback, just a launchd respawn that drops every live session.
And here is the insight that follows from it, which the codebase is scrupulously honest about. If all inference is serialized behind one lock, then running N sessions at once on a single Mac is queueing, not throughput. The concurrency module refuses to call it throughput anywhere. It labels the metric explicitly: measures latency degradation under concurrent load (single-box MLX inference is lock-serialized); NOT parallel throughput.
They even keep the LLM deliberately out-of-process (LM Studio over HTTP) specifically so its slow reasoning can overlap outside the lock: the one part of the pipeline that is allowed to run concurrently is the part that does not touch MLX directly.
Now measured: that degradation scorer had no committed run, so I ran it for this post. At one session, time-to-first-audio averaged 3.71s; at three simultaneous sessions, 10.54s (p95 14.7s). A 2.84x slowdown. Queueing, not throughput, with a number behind it now. The architectural claim (single-box MLX is serial) was always solid in the code; this puts a figure on what it costs.
The unified-memory win: batch-8 TTS is 5.45x faster for +6% memory
Here is the upside of Apple Silicon that genuinely surprised me.
On the same model, batching multiple TTS requests together is nearly free in memory. Measured on 6-bit Qwen3-TTS with a short prompt.
| Batch | TPS | Throughput | Avg TTFB | Memory |
|---|---|---|---|---|
| 1 | 20.8 | 1.67x | 84.8ms | 3.88GB |
| 2 | 34.7 | 2.78x | 78.0ms | 3.92GB |
| 4 | 53.2 | 4.26x | 99.9ms | 3.98GB |
| 8 | 68.1 | 5.45x | 140.5ms | 4.10GB |
Go from batch-1 to batch-8 and you get 5.45x the throughput for an extra 0.22GB: memory rises from 3.88GB to 4.10GB, about 6%. On a GPU with dedicated VRAM, 8x the batch would cost you something close to 8x the activation memory. On Apple's unified memory, the weights are shared and only the activations grow, so the batch is almost free.
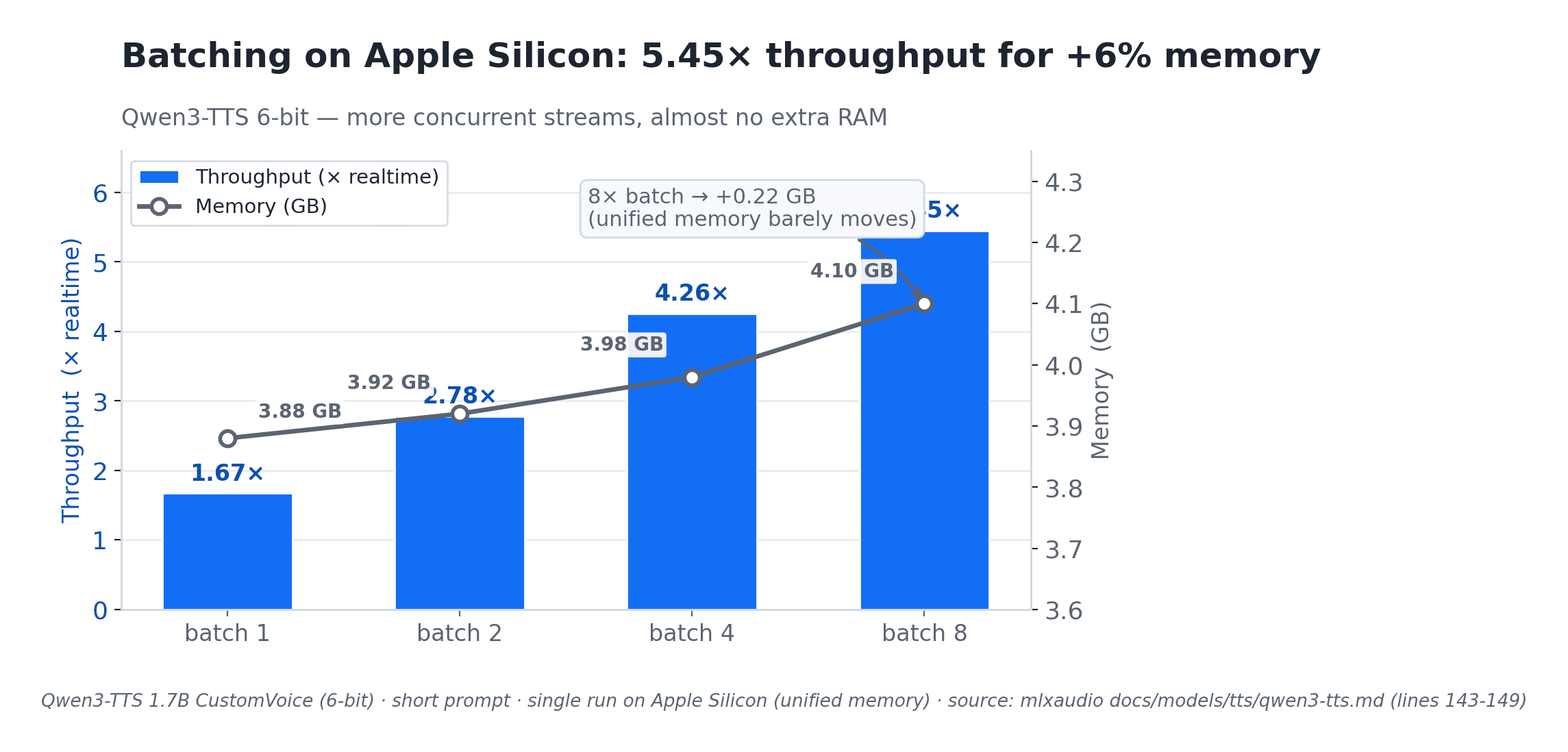
That is the unified-memory advantage for inference: you can batch aggressively without paying for it in RAM, provided your traffic is batchable in the first place. It is the opposite shape from the live-voice case in the previous section, where one-at-a-time turns cannot be batched and the lock just queues them.
Soft-number flag: single-machine, single-run, short-prompt only. Longer prompts will shift the time-to-first-byte and tokens-per-second columns.
The reproducible part: how to actually run this
Numbers are only useful if you can reproduce them. Here is the practical core.
The server speaks the OpenAI audio API, so existing clients work by pointing the base URL at localhost. Text-to-speech, POST /v1/audio/speech, get WAV back:
curl -X POST http://localhost:8000/v1/audio/speech \
-H "Content-Type: application/json" \
-d '{"model": "mlx-community/Kokoro-82M-bf16", "input": "Hello!", "voice": "af_heart"}' \
--output speech.wavSpeech-to-text, POST /v1/audio/transcriptions, multipart upload:
curl -X POST http://localhost:8000/v1/audio/transcriptions \
-F "[email protected]" \
-F "model=mlx-community/whisper-large-v3-turbo-asr-fp16"Convert and quantize any HuggingFace model in one command:
python -m mlx_audio.convert \
--hf-path prince-canuma/Kokoro-82M \
--mlx-path ./Kokoro-82M-4bit \
--quantize --q-bits 4The guidance that matters: 4-bit is usually the sweet spot for TTS. TTS models get sensitive at 3-bit. And the rule I would tattoo on anyone shipping voice: always listen to the output, because word-error-rate does not capture prosody degradation. A 3-bit model can score fine on WER and still sound subtly drunk.
Three things will bite you in production, and one of them is counterintuitive.
- The first request hangs about 60s. Cold MLX models download weights and compile kernels on first call. OpenWebUI's default 60s timeout will fire; a voice satellite drops the session in about 5s. Pre-warm by hitting POST /v1/models?model_name=... on boot before any user request.
- Drop your worker count to 1. This is the counterintuitive one. The usual reflex for a slow server is add workers. Here, the opposite is correct: each uvicorn worker loads its own roughly 4GB copy of every model, so more workers means workers dying of out-of-memory. The fix is to run a single worker and rely on async I/O, which ties directly back to the single-lock design above. There is no throughput left on the table by going to one worker, because the MLX lock already serializes inference anyway.
- Turn off autoload in production. With MLX_AUDIO_AUTOLOAD_ON_REQUEST=false, a request for an unloaded model returns a clean HTTP 503 with Retry-After: 60 instead of a 60-second synchronous hang.
A reproducibility footgun, found while re-measuring for this post. Timing the TTS endpoint myself, I hit a sharp edge worth passing on: the running server returns HTTP 200, starts the stream, then crashes it mid-response (curl exits 18, zero bytes) if you call /v1/audio/speech on a VoiceDesign model without an instruct field. The actual cause (ValueError: VoiceDesign model requires 'instruct') only appears in the server's error log, never in the HTTP response. If you benchmark a local server and get empty audio behind a 200, read the server's error log before you blame your client.
One Apple-dev gotcha if you build the Swift framework: Xcode Beta ships without the Metal Toolchain, so the mlx-swift .metal shaders will not compile. You will see error: cannot execute tool 'metal' due to missing Metal Toolchain. Fix it with one download (about 688MB):
xcodebuild -downloadComponent MetalToolchainIn the spirit of truth over hype: 18 of 19 models worked. The one that did not was OuteTTS 1.0 0.6B. Its snapshot generated insufficient audio codebook tokens (8 of one codebook, 0 of another, out of 300 expected). That is an MLX conversion problem, not a model problem, and I could not salvage it. Sometimes the answer is this one is broken, move on.
What I actually took away
- A warm microbenchmark is not a production latency. The roughly 100x spread between models is one gap; the roughly 46x gap between the fastest warm benchmark (0.19s) and the measured production time-to-first-audio (8.8s p50) is the one that will surprise you.
- Some problems live in the weights, not the config. A reasoning model that will not stop thinking needs a serving-layer lever or a different model. No flag will fix training.
- On one Mac, concurrency is a queue. Single-box MLX inference is serialized; I measured a 2.84x slowdown at three sessions. Plan for queueing, batch when you can, and keep the slow out-of-process pieces out of the lock.
- Unified memory genuinely pays off (batch-8 for +6% RAM), but only when your workload is batchable.
And the meta-lesson: the most useful artifact in that project was a comment admitting the 0.19s model takes several seconds in production, plus an eval I could re-run to prove it takes even longer than the comment said. Write down the embarrassing number. Then build the harness that re-checks it. It teaches you more than the flattering one ever will.
Provisional figures (single-machine M3 Ultra / 512GB, mostly single-run): every absolute latency in the 18-model table and the batching curve. Re-measured and now logged: production time-to-first-audio (p50 8.8s), concurrency degradation (2.84x at three sessions), warm Qwen3-TTS-1.7B (about 1.5s). Still soft: the 17 to 25s reasoning latency and about 1.1s post-fix time-to-first-token (from a code comment), the 30 to 60s cold start (could not restart the shared server), and the original 0.19s Kokoro figure (not loaded, not reproduced today). Rankings and ratios are solid; exact milliseconds are one machine's reading and should be hardened before being quoted as universal.