
The short version
I swapped Fable 5 into the middle of a live autonomous development session. That accident gave me a useful comparison: same project, same harness, same long-running task, same session state, but a different frontier model in the orchestrator seat.
This is not a benchmark. It is a field note from one production-grade autonomous development system. The numbers are real, but the point is practical: would I keep Fable 5 as the orchestrator?
Yes.
And I want to be clear about magnitude, because the charts understate it. In daily use this is not an incremental upgrade. Fable produced better code, better analysis, fewer interventions, and needed less steering — and the difference reads in multiples, not percentage points. It is a generational leap, and I would use it for everything if the economics made sense.
They do not, yet. With the harness in place, Fable 5 got more done with fewer words, used the verification system better, and made fewer self-inflicted mistakes against the harness rules. But it also exposed a cost problem immediately: unless the harness forces cheaper subagent delegation, Fable will happily let frontier-model pricing leak into work that does not need a frontier model.
The decision I came away with is simple: Fable 5 keeps the orchestrator seat, with explicit cost guardrails. Fable is awesome — and it is only cost-viable as part of a harness and a model portfolio. As the one model that does everything, it is a token furnace unlike anything I have measured.
What changed after the swap
My development pipeline works like a small factory. A frontier model sits in the orchestrator seat, breaks features into work packages, dispatches builder subagents, reviews their work, and gates the result through verification harnesses before code lands.
The harness was already mature. It had been tuned around Claude Opus 4.8's habits, strengths, and failure modes. Fable 5 entered that environment cold, mid-session, while a long-running task was already underway. Opus 4.8 handled the first part of the session, then Fable 5 picked up the same conversation and continued from the existing project state.
- 66 commits across 8 features in the measurement window.
- 13 orchestrator session transcripts.
- A 49,000-row decision log.
- Harness builds 2.1.165 through 2.1.170.
- A crossover session with 12,370 transcript lines: 1,426 tool calls under Opus 4.8 before the swap, 123 under Fable 5 after.
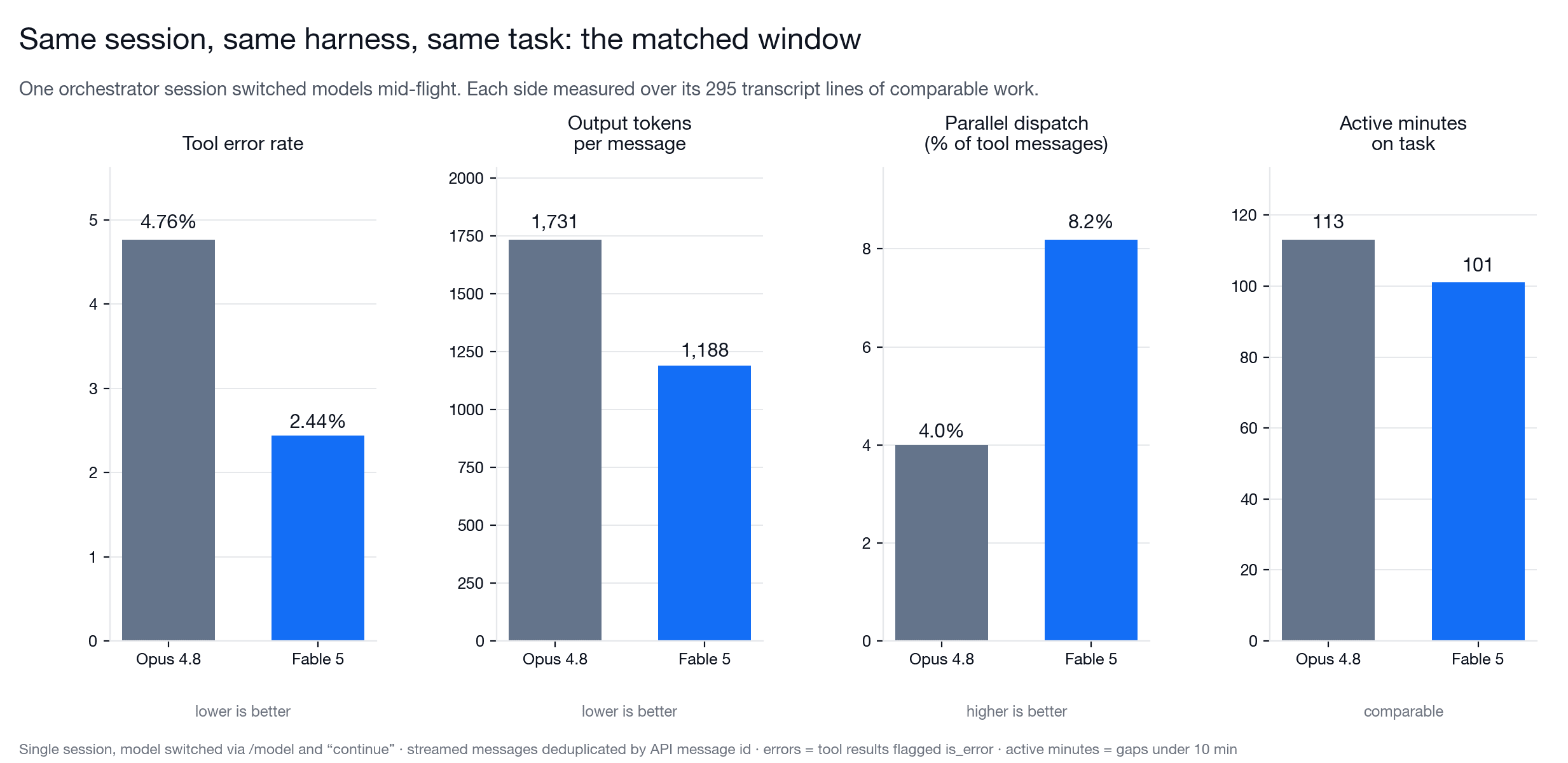
For the cleanest comparison, I used the crossover session itself. Fable's segment after the swap covered 295 transcript lines, so I compared it against Opus's final 295 lines before the swap. Both models were working on the same project, in the same session, on the same harness build.
| Metric | Opus 4.8 | Fable 5 | Change |
|---|---|---|---|
| Tool error rate | 4.76% | 2.44% | -49% |
| Output tokens | 269,565 | 155,575 | -42% |
| Output tokens per message | 1,731 | 1,188 | -31% |
| Parallel dispatch rate | 4.0% | 8.2% | 2.0x |
| Active minutes | 113 | 101 | comparable |
The practical read: Fable did similar orchestration work with much less output, more parallelism, and fewer tool errors in the matched window. The token difference matters. Fable used 42 percent fewer output tokens, and its messages averaged 31 percent shorter. It was not simply doing less; it was spending fewer words on the same kind of orchestration work: reading state, making decisions, launching work, and reviewing results.
It also resumed quickly. Thirty-four seconds after I typed "continue," Fable had read the experiment leaderboard, understood the state of the multi-day session, and made its first substantive change: extending the search axes of the running experiment. That was the first useful signal. Fable could pick up an inherited orchestration context without a long warm-up.
The failure rate was not the story. The failure type was.
The easiest mistake would be to say "Fable fails less." That is not what the broader crossover data shows. Across the full crossover segments, excluding user rejections, genuine tool failure rates were almost the same: 1.54 percent for Opus, 1.63 percent for Fable. So the claim is not "Fable has a lower overall failure rate." In this run, the overall failure rate was basically the same. The difference was what kind of failures each model produced.
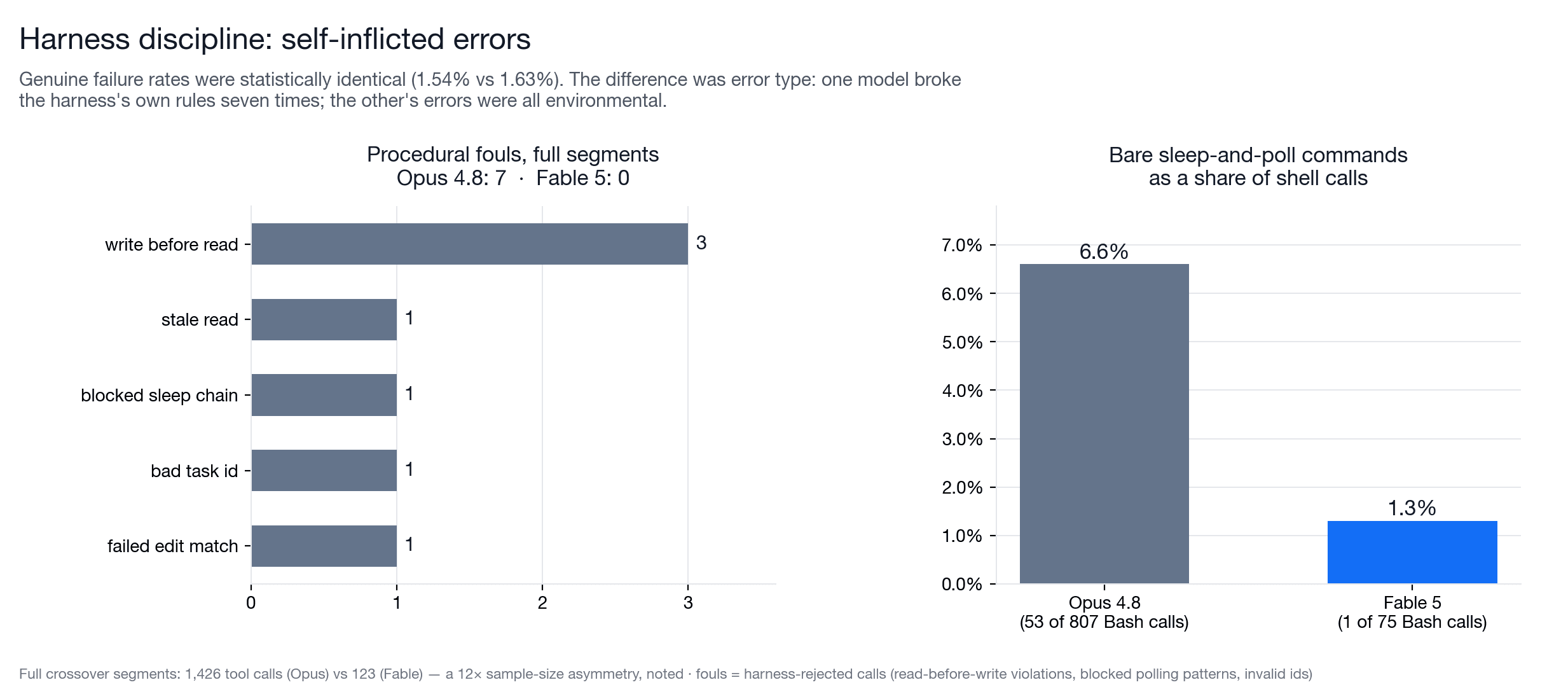
Across 1,426 tool calls, Opus committed seven procedural fouls that the harness had to reject:
- Three attempts to write files it had not read.
- One write against a stale read.
- One invalid task id.
- One failed edit match.
- One blocked polling pattern.
It also used bare sleep-and-poll shell commands for 6.6 percent of its shell calls. Fable's 123 calls produced zero procedural errors. Its failures were one user rejection and two genuine environment problems. The sample sizes are uneven, but the behavioral difference was obvious in the transcripts: Fable spent less motion fighting the harness.
That is the more useful takeaway. Fable did not magically eliminate failures. It made fewer of the annoying, self-inflicted mistakes that slow an autonomous development harness down.
The bigger difference: Fable paid for verification earlier
The most important change was not speed. It was sequencing. Fable moved verification earlier in the work. In its runs, Fable tended to build the verification harness before or alongside the first implementation work package. It baselined the harness red against the unbuilt feature, then mutation-tested layers to prove the checks could actually fail.
It also used the external review model differently. Instead of waiting until product code existed, Fable pointed the adversarial reviewer at the harness itself. In one case, the harness went through three adversarial rounds and seventeen fixes before the first builder was dispatched.
That changed where defects were caught.
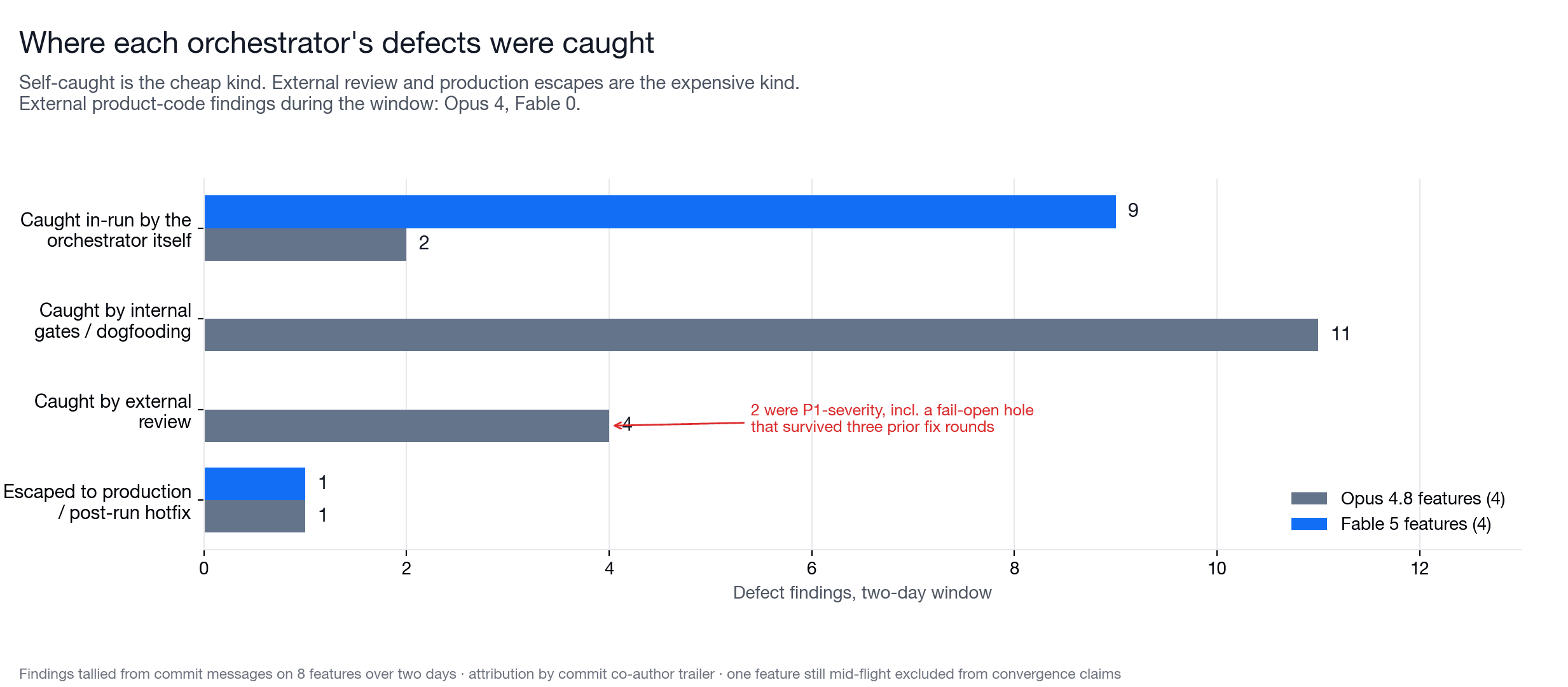
Across the feature window, Opus features had four external-review findings on product code, including two P1s. One of those was a fail-open validation hole in an anti-fraud check that survived three internal fix rounds before an external review committee flagged it. Opus also had one regression escape to production. Fable features had zero external-review findings on product code during the window. Its defects were caught by its own mid-run interventions and by rerunning its own verification harnesses before declaring the work done.
That does not mean Fable shipped perfectly. It did not. The chat interface overhaul shipped one user-visible defect that its 19-layer verification harness missed: a persistence bug that wrote one text fragment per streamed token. It was hotfixed about three hours later. The hotfix was good: it named the causing commit and repaired both the write path and the already-corrupted rows. But an escape is still an escape. In this window, each orchestrator had one.
The difference was where the other problems surfaced. With Opus, more defects made it to post-hoc gates, dogfooding, or external review. With Fable, more defects were caught while the feature was still being shaped. That is a meaningful operational difference because early defects are cheaper. A failing verifier before implementation is a design tool. A P1 from external review after multiple fix rounds is rework.
Feature outcomes
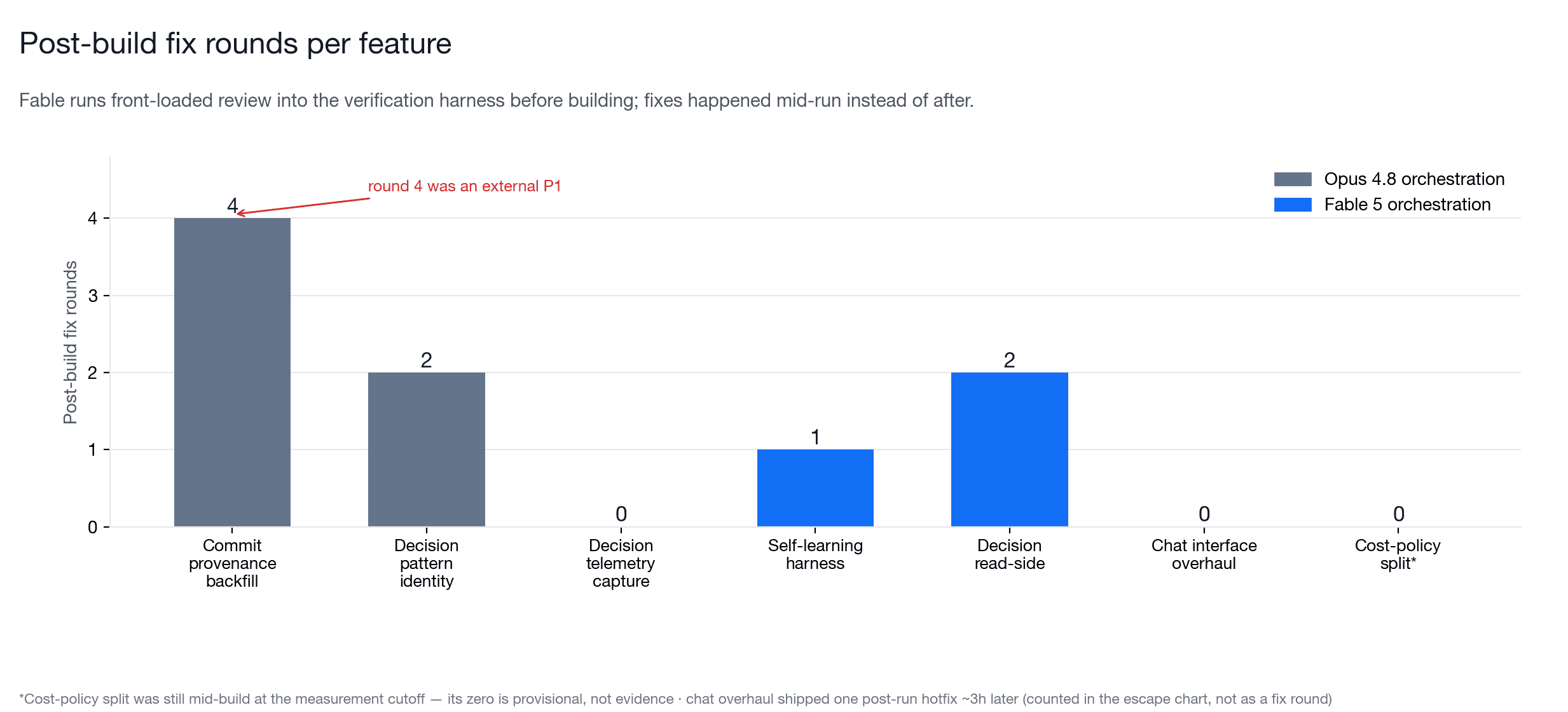
| Feature | Orchestrator | Build window | Commits | Fix rounds |
|---|---|---|---|---|
| Commit provenance backfill | Opus 4.8 | 74 min + 2-day tail | 5 | 4 |
| Decision telemetry capture | Opus 4.8 | 67 min | 8 | 0 |
| Decision pattern identity | Opus 4.8 | ~50 min + next-day fix | 8 | 2 |
| Self-learning harness | Fable 5 | 61 min | 9 | 1 |
| Decision read-side | Fable 5 | 201 min | 7 | 2 |
| Chat interface overhaul | Fable 5 | 153 min | 13 | 0 |
| Cost-policy split | Fable 5 | 18.6 min, mid-flight | 4 | n/a |
The table is not a difficulty-matched benchmark. These were real features, not lab tasks. But as production telemetry, the pattern is useful: Fable's work felt less like "build, then clean up" and more like "build the rails, prove the rails, then send builders through them." That is exactly what I want from an orchestrator.
Calibration mattered too
The crossover session was running an automated experiment loop, so both models reported on the same accuracy metric a few hours apart. Opus reported the improvement directly: the metric had gone from 0.066 to 0.184, a 2.8x climb from the recipe axis alone.
Fable gave me the more useful answer. Asked whether 0.184 was meaningful, it framed the result as a signal, not yet a capability. Then it pointed out that the eval was n=80, the standard error on 0.184 was roughly ±0.04, and the three-way tie at the top was inside noise.
That changed the next decision. Instead of over-tuning against a small eval, the system moved toward collecting more data. This is why calibration matters in an orchestrator. The orchestrator is not just writing code. It is deciding what to believe, what to dispatch, and what to measure next. A better status report compounds into better downstream decisions.
The leap is biggest outside the code
The matched window measures orchestration mechanics. The gap I cannot fully chart is judgment, and that is where Fable is furthest ahead. It is noticeably smarter on non-coding work: problem evaluation, analysis, decomposition, the PM-style thinking that decides what gets built and in what order. It also needs less context to get there. The human-obvious assumptions — the things you would tell a sharp colleague in one sentence and a junior engineer in three paragraphs — it tracks on its own. Picking up a multi-day session in thirty-four seconds, error-barring its own results unprompted, designing verification layers that anticipate how a builder might game them: those are all the same underlying skill, and it is the skill that matters most in the seat that decides everything else.
That changes which seats earn frontier pricing. The challenge with a model this good is narrowing its scope to use that intelligence at the right points, and orchestrator — with review and ultimate accountability — is the best cost-benefit seat I have found. One mind whose judgment compounds across everything below it. Analysis and PM-style work will see the same outsized benefit for the same reason. Builder work, the bulk of the volume, is where a strong harness and cheaper models still win on economics.
And to be equally clear about the ceiling: this is still not the set-it-and-forget-it model we are all waiting for. The escaped streaming defect shipped past a 19-layer harness and needed a human to notice it. Developer review remains load-bearing. The leap is real; the supervision requirement did not disappear with it.
The cost problem showed up immediately
Fable was faster, terser, cleaner, and more aggressive about parallel work. That is good. It is also dangerous if the harness does not control delegation cost.
The concrete failure was model selection for subagents. When Opus dispatched builder subagents, it usually tagged them with a cheaper model. Out of 96 Opus spawns, 62 ran on a mid-tier model and 20 ran on a standard one. Opus even dispatched an eight-wide review swarm entirely on the mid-tier model. Fable did not do that. It passed an explicit model parameter on zero of its 15 spawns. Every builder silently inherited the expensive frontier model from the orchestrator seat.
That is not a small implementation detail. At Fable's launch pricing — 10 dollars per million input tokens and 50 dollars per million output — it changes the economics of the whole system. The fix was not to stop using Fable. The fix was to make cost policy explicit. After I called out the problem, Fable wrote itself a standing rule: builder spawns must include an explicit cheaper model unless there is a reason to spend frontier tokens.
That is the right lesson, and it is the portfolio principle in one sentence: Fable at the top, deciding; cheaper models underneath, doing. A strong orchestrator should choose where expensive judgment is needed, not accidentally route every worker through the most expensive model because the default was inherited. Run Fable solo, as the one model for everything, and the same speed and parallelism that make it impressive turn it into the most expensive way to work I have ever measured. One afternoon of untagged subagents made that obvious on the usage graph before any analysis did.
Here is the part that makes "token furnace" literal rather than rhetorical. Per session, Fable writes leaner — that was the matched-window result. As a fleet, it is another animal. With five concurrent sessions and their subagent swarms running, Fable's hottest hour produced 593,845 output tokens — 2.7 times the highest hour Opus ever recorded in this harness. Inside that hour was a ten-minute stretch that produced 196,880 output tokens on its own, a 1.18-million-token-per-hour pace. That is the stretch where I watched most of a five-hour usage window disappear in about ten minutes.
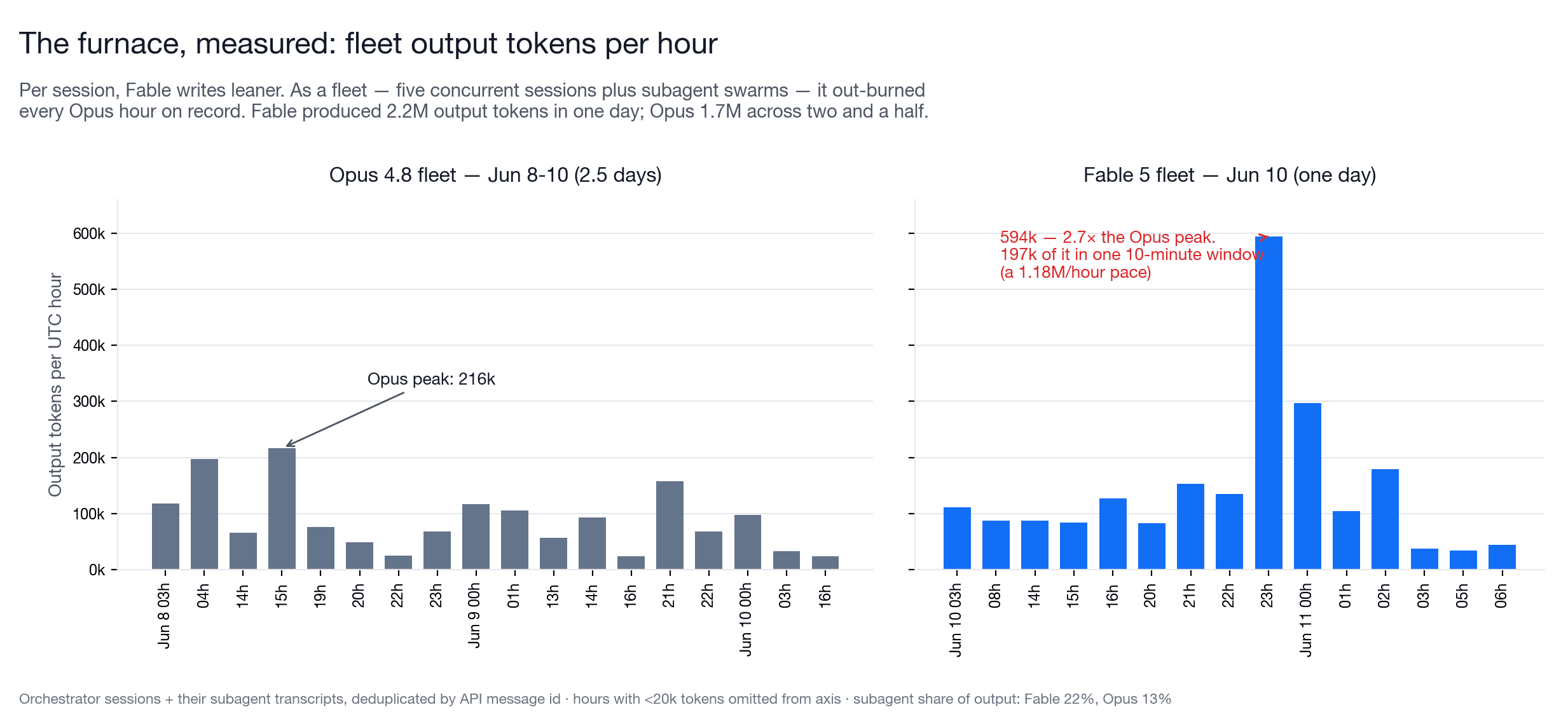
The day totals say the same thing. Fable produced 2.2 million output tokens in a single day; Opus produced 1.7 million across two and a half. And 22 percent of Fable's output came from subagents, against 13 percent for Opus — more delegation by volume, all of it inheriting frontier pricing until the harness rule landed. At one point I rejected a dispatch wave mid-flight because an earlier swarm of 37 agents had already eaten nearly three quarters of a usage window on its own. The furnace is a fleet behavior, which is exactly why it has to be a harness rule and a model portfolio, never a per-prompt habit.
Just because it can does not mean it is worth it
The output side is only half the furnace. The other half is reading. Fable will read mountains of data because it can, and it is genuinely good at it — long-context retrieval is one of its strengths. The problem is what that habit costs at frontier pricing. Across one day, the Fable fleet read 1.06 billion cache tokens. At list pricing, the day's work bills out around 1,450 dollars — and 92 percent of that is the reading, not the writing.
The bursts are what catch you. The hottest twenty minutes of data-heavy work billed about 108 dollars at list rates; the hottest hour, about 289. A few stacked sessions doing transcript parsing, log sweeps, and database reads will run into hundreds of dollars before you notice anything is wrong, because nothing is wrong — the model is doing exactly what you asked, competently, at the most expensive possible tier.
So the harness now enforces two rules that did not exist before this run. First, subagents with summaries and outcomes are required: a subagent returns a condensed result — what it found, what it concluded, what changed — never a raw data dump into frontier context. Second, data-heavy reading is segmented and human-driven: bulk sweeps get scoped deliberately, and the mechanical parts — parsing logs, grepping transcripts, aggregate queries — go to deterministic, harness-driven lighter agents or plain scripts that produce the same answer at a fraction of the cost.
That is the takeaway in one line: just because Fable can read everything does not mean it is worth paying frontier rates for it. The capability is real. The judgment about when to use it has to live in the harness.
Throughput was better, but I trust it less
The throughput numbers favor Fable, but they are the least clean part of the dataset. Measured over active hours, meaning clock hours containing at least one commit: 4.09 commits per active hour for Opus, 5.25 for Fable. Adjusted net lines per active hour: 1,925 against 3,306. The line-count number excludes an intentional 90,000-line dead-code sweep from the Opus side; counting that planned deletion against throughput would make the comparison useless.
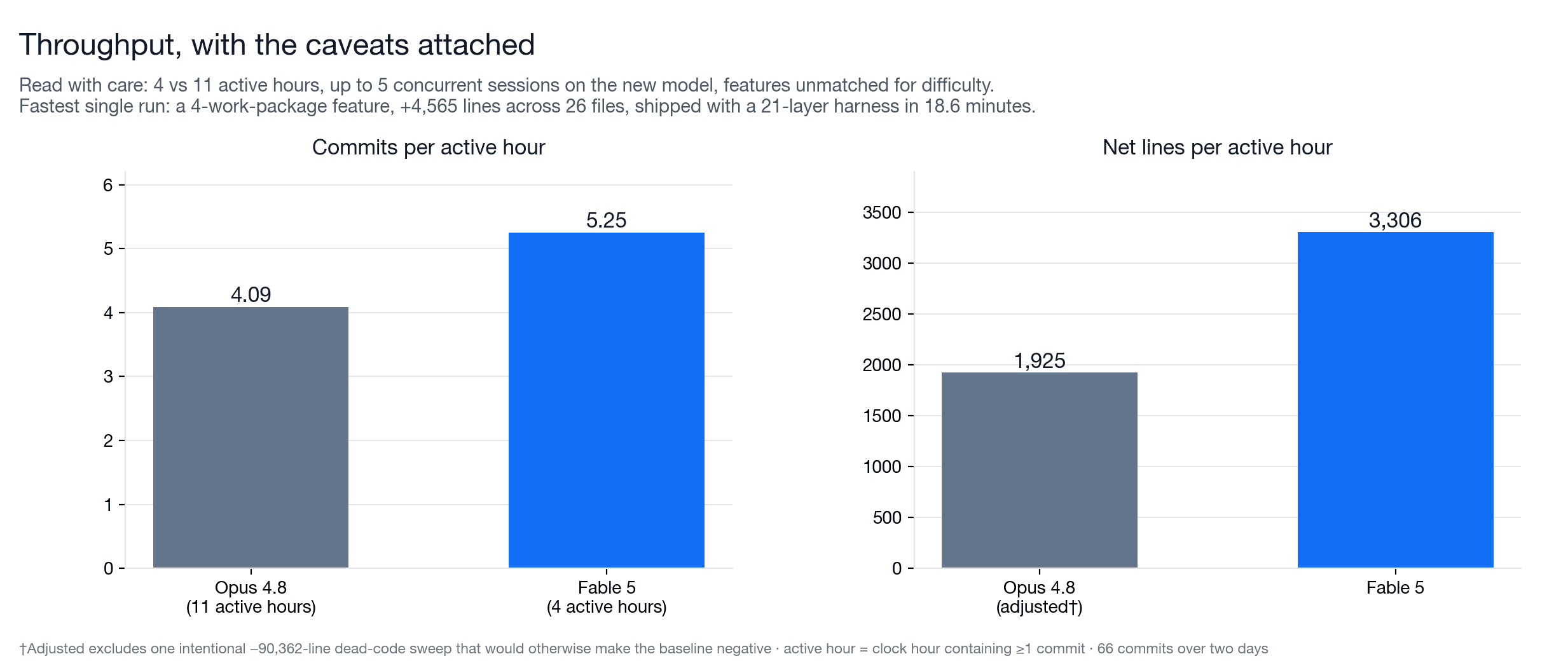
Even after that adjustment, treat these as directional. The windows were not equal: roughly 11 active hours on the Opus side versus 4 on the Fable side. Still, the production behavior was hard to miss. The most striking Fable run went from first commit to a four-work-package implementation in 18.6 minutes of wall clock: 4,565 lines added across 26 files, gated by a 21-layer verification harness, with builders dispatched in parallel waves.
Fable also did something Opus did not attempt in this window: it ran up to five orchestrator sessions concurrently, each driving its own feature. That concurrency inflates per-hour numbers, but it is also part of the capability being measured. An orchestrator that can safely keep more work in flight is more valuable than one that can only move serially.
How I read the data
I would not read this as a universal model benchmark. I would read it as a harness-specific production trial. The strongest findings are the ones closest to the mid-session swap: same session, same harness build, same project state, same task family. In that matched window, Fable used 42 percent fewer output tokens, produced 31 percent shorter messages, doubled the parallel dispatch rate, and had a lower tool error rate.
The broader feature data is less controlled but more operationally meaningful. There, Fable's main advantage was not "no defects." It was better defect placement. It spent verification effort earlier, caught more problems before external review, and treated the harness as part of the product rather than as a final exam.
The main downside was cost discipline. Fable's speed and parallelism make it easy to spend too much unless the harness forces explicit model choices for subagents.
Why I can test a new model the day it ships
The harness does not make any of this easy. It makes it possible. Putting a day-old frontier model in charge of a production development pipeline is normally a leap of faith; the harness is what turns it into a measurable trial. I run this exact analysis on every model change, and the harness is built for it: every orchestrator session is logged, every decision is recorded, every commit carries model attribution, every verification run leaves artifacts. When a new model takes the seat, the telemetry to judge it already exists. The question "is the new model better, and where does it leak money" is answerable from data the system was already collecting.
That is why the tuning landed in hours, not weeks. The untagged-spawn problem was visible on the usage graph the same afternoon it started; the spawn-path rule that fixes it shipped the same day, built by Fable itself in 18.6 minutes. The subagent summaries-and-outcomes contract came straight out of the read-side numbers. By the time this post went up, the adjustments this round's data called for were already in place:
- Fable 5 kept the orchestrator seat. The matched window and the feature behavior both justified it.
- Model delegation is explicit. Builder and reviewer spawns no longer inherit the frontier model; cheap-model delegation is enforced at the spawn path as a harness rule, not a suggestion.
- Verification-first sequencing is the expected order. The best Fable behavior was building and testing the verifier before trusting the implementation, so the harness now expects it.
- Small eval wins are treated as signals, not proof. The 0.066 to 0.184 jump was worth pursuing, but Fable was right about the noise. More data was the correct next step, and that is the path the system took.
- Escape tracking continues. Opus had more soak time in this window. Fable's escape count can still rise as its features spend more time in production, and the telemetry is watching for it.
- Subagents return summaries and outcomes, not raw data. Bulk reading is segmented and human-driven, and mechanical sweeps go to deterministic, harness-driven lighter agents. Frontier context is for judgment, not for holding mountains of data.
The model is the swappable part. The harness and its analytics are the durable asset. They are what make it possible to test the latest model the day it ships, adopt it the day after, and tune around its weaknesses before they get expensive — and they are why the next model change will get this same writeup, with the same charts, just as fast.
Bottom line
Fable 5 is a generational leap, and I am saying that as someone who distrusts launch-week superlatives on principle. Better code, better analysis, fewer interventions, less steering — in multiples. I would use it for everything if I could. Not because it never fails; it does. Not because this was a clean benchmark; it was not.
It earned the seat because it made better orchestration moves: fewer wasted tokens, shorter messages, more parallel dispatch, cleaner harness discipline, earlier verification, better calibration around noisy results, and sharper judgment everywhere judgment was the bottleneck. The tradeoffs are just as real. The cost does not make sense for everything — run solo it is a token furnace unlike anything we have seen — and it still requires enough developer review that nobody should mistake it for set-it-and-forget-it.
So the practical verdict: a generational leap that still needs the same principles applied in the harness to be effective at scale and in production. Put it in the seats where judgment compounds — orchestrator, analysis, problem evaluation — keep the harness in charge of cost and review, and the trade is easily worth making. Still waiting for the day the harness doesn't matter. Today is not that day.